NNS16-00-Mở đầu
Sơ lược về trí tuệ nhân tạo
Trí tuệ nhân tạo có thể chia làm hai trường phái chính là: trí tuệ nhân tạo cổ điển (Classical AI, CAI) và trí tuệ nhân tạo hiện đại (Modern AI, MAI). Mặc dù tên gọi có vẻ khác biệt về mặt thời gian, hai trường phái này thực sự xuất hiện gần như cùng lúc, vào khoảng những năm 1940 khi máy tính bắt đầu được xây dựng (chúng ta không cho những công trình toán học, triết học cổ xưa về hoạt động tư duy của con người là thuộc trí tuệ nhân tạo).
Trí tuệ nhân tạo cổ điển thường dựa trên việc tìm kiếm lời giải trong một cơ sở tri thức xác định trước. Để hệ thống có thể hoạt động được, lập trình viên phải chỉ rõ cách thức để tìm kiếm, suy luận và đưa ra quyết định. Hướng tiếp cận này đã đạt được những thành công đáng kể khi xây dựng nên những hệ chuyên gia (expert systems), những chương trình chơi cờ đánh bại các nhà vô địch thế giới, …
Tuy nhiên phương pháp này gặp phải rất nhiều khó khăn khi giải quyết những bài toán mà con người có thể dễ dàng giải được nhưng chính chúng ta cũng không biết ta thực hiện nó như thế nào, ví dụ như việc dạng đồ vật hay đọc hiểu một đoạn văn bản. Để hiểu được một văn bản, theo cách tiếp cận của CAI, chúng ta phải liệt kê toàn bộ các luật ngữ pháp và ý nghĩa của từng từ trong từng ngữ cảnh khác nhau. Việc đó là vô cùng tốn kém thậm chí là không thể bởi số lượng các luật là rất lớn và số lượng ngữ cảnh còn lớn hơn rất nhiều tới mức gần như là vô hạn. Phương pháp trên còn cực kì nhạy cảm với việc thay đổi bài toán, một hệ thống nhận dạng văn bản tiếng Anh không thể sử dụng cho tiếng Việt và càng không thể sử dụng cho việc nhận dạng ảnh được, chúng ta cần phải xây dựng một cơ sở tri thức hoàn toàn mới cho mỗi bài toán mới. Do đó, chúng ta cần những phương pháp mới có khả năng tự động phát hiện các quy luật và tự động thích nghi với những bài toán mới. Đó chính là mục tiêu của trí tuệ nhân tạo hiện đại và phương pháp phổ biến nhất, gần như chiếm trọn trí tuệ nhân tạo hiện nay là học máy (Machine Learning, ML).
Học máy
Định nghĩa
Với trí tuệ nhân tạo cổ điển, khi mà muốn máy tính hoàn thành một nhiệm vụ thì lập trình viên phải chỉ rõ trong code (mã nguồn) cách thực hiện nhiệm vụ đó như thế nào. Trong khi đó ML, nói một cách đơn giản là tập hợp của những phương pháp giúp cho máy tính có thể học được cách thực hiện những nhiệm vụ đó mà không cần sự chỉ dẫn trực tiếp của con người (Arthur Samuel, 1959).
Những bài toán được giải quyết bởi ML thường là
- Những bài toán có quy mô lớn như việc xử lí dữ liệu web, dữ liệu đa phương tiện (multimedia), dữ liệu từ cảm biến (sensors), …
- Những bài toán quá phức tạp mà chúng ta không biết lời giải dạng hiện (closed form solution) hoặc không thể lập trình bằng tay được như thị giác máy tính (Computer Vision, CV, giúp cho máy tính có khả năng nhận biết thế giới qua hình ảnh tương tự như thị giác con người), xử lí ngôn ngữ tự nhiên (Natural Language Processing, NLP, giúp cho máy tính có khả năng hiểu được ngôn ngữ của con người), điều khiển robot, xe cộ trong môi trường tự nhiên, …
Một số ví dụ cụ thể về bài toán phù hợp với ML như:
- Tìm kiếm trên web: hàng ngày chúng ta cần phải tìm rất nhiều thông tin trên web, việc dùng người duyệt qua hàng tỉ trang web để tìm thứ phù hợp là không khả thi. Các thuật toán ML có khả năng tính toán độ phù hợp giữa câu hỏi của người dùng (query) và nội dung của các trang web và sắp xếp chúng theo thứ tự để trả về cho người dùng.
- Lọc spam mail: các hệ thống lọc spam cần phát hiện nhưng email có nội dung khác thường và lừa đảo và ngăn chúng tới được inbox của người dùng. Khác biệt với bài toán trên, chúng ta cần phát hiện ra sự bất thường, đo đạc sự khác nhau giữa những email thông thường và spam.
- Nhận dạng ảnh: khác với văn bản, khi mà một ý tưởng thường chỉ có một số nhỏ cách diễn đạt và các cách diễn đạt thường sử dụng những từ ngữ giống nhau hoặc đồng nghĩa, ảnh chụp của cùng một vật thể ở mỗi góc độ khác nhau, điều kiện môi trường khác nhau thì có thể rất khác nhau nếu so sánh ở từng điểm ảnh. Các hệ thống xử lí ảnh cần phải nhận ra những đặc trưng bất biến (invariants) trong những bức ảnh để có thể đạt được độ chính xác cao
Định nghĩa: Bài toán ML một chương trình A được gọi là học từ kinh nghiệm E(xperience) để thực hiện một nhiệm vụ T(ask) nếu như hiệu quả thực hiện P(erformance) của nó tăng lên sau khi được bổ sung E.
Huấn luyện và kiểm tra
Quá trình xây dựng một hệ thống ML thường bao gồm hai giai đoạn: huấn luyện và kiểm tra.
Huấn luyện Quá trình dạy một hệ thống ML học gọi là huấn luyện (training). Huấn luyện thường là việc đưa cho hệ thống ML những ví dụ mẫu (training example) và dựa trên những ví dụ đó, hệ thống phải hiệu chỉnh các tham số (parameters) của mình để có thể cho ra được kết quả đúng ở những ví dụ sau. Quá trình hiệu chỉnh tham số thường sử dụng các thuật toán tối ưu (optimization ví dụ convex optimization, linear optimization, …) và quy hoạch (programming, ví dụ dynamic programming, approximate dynamic programming, …) và nhiều phương pháp toán học, thống kê khác.
Kiểm tra Sau khi hoàn thành huấn luyện, hiệu năng (performance) của một hệ thống thường được ước lượng bằng hiệu năng của nó trên một tập dữ liệu kiểm tra (test set) khác với tập huấn luyện (training set). Quá trình này gọi là kiểm tra (testing) nhằm ước lượng hiệu quả thực sự của hệ thống trong môi trường làm việc. Test set bắt buộc phải khác với training set vì hệ thống được huấn luyện trên training set nên nó sẽ dần thích nghi với những đặc điểm của training set và đạt được hiệu năng cao trên tập này, không phản ánh hiệu năng thực tế của hệ thống trong môi trường làm việc.
Sự tương đồng Quá trình training và testing giống như quá trình dạy học và thi cử trong đời sống. Trong quá trình dạy, giáo viên đưa cho sinh viên rất nhiều bài tập và qua quá trình giải các bài tập đó, sinh viên dần hiểu được bản chất của vấn đề. Tương tự như vậy, chúng ta đưa cho hệ thống ML rất nhiều ví dụ và qua các ví dụ đó, hệ thống dần dần xây dựng hiểu biết về bài toán. Thi cử là để đánh giá hiểu biết của sinh viên, nếu giáo viên đưa cho sinh viên những bài toán đã dùng trong quá trình giảng dạy, sinh viên sẽ dễ dàng đạt được điểm cao hơn hiểu biết thực sự của họ về vấn đề. Do đó, bài toán trong đề thi cần phải khác với những bài toán sử dụng trong quá trình dạy học. Năng lực thực sự của sinh viên, giống như hiệu năng hệ thống ML, là những đại lượng ẩn (hidden variables), chúng ta ước lượng nó thông qua thi cử. Đến đây thì có lẽ mọi người đều hiểu rõ vì sao có tên gọi Machine learning. Tuy nhiên, khi dịch sang tiếng Việt là học máy thì nghe không được xuôi tai cho lắm, :v.
Phân loại hệ thống ML
Các hệ thống ML được phân loại theo cách thức mà người ta huấn luyện nó. Một số nhánh chính của học máy bao gồm:
Học có giám sát (Supervised learning, SL)
Phương pháp này được gọi là có giám sát vì trong quá trình huấn luyện, hệ thống ML cần phải biết được câu trả lời chính xác cho mỗi training example. Với mỗi example, hệ thống đo đạc sự khác nhau giữa câu trả lời đúng và câu trả lời mà nó đưa ra. Mục tiêu của training là làm giảm độ sai lệch giữa tập hợp câu trả lời đúng và tập hợp câu trả lời của hệ thống. Mỗi mẫu dùng để huấn luyện bao gồm 2 phần: các đặc trưng để mô tả vật mẫu (features) và nhãn của mẫu (label).
Ví dụ một hệ thống SL dùng để phân loại trái cây thì mỗi training example sẽ có thể có dạng như sau: (màu sắc, vị, cân nặng : tên loại quả), (đỏ, ngọt, 130gram : táo), (vàng, chua, 200gram : cam), … Độ sai khác cho mỗi mẫu là 1 nếu như hệ thống đưa ra câu trả lời sai, 0 nếu câu trả lời đúng. Độ sai khác được tính cho toàn bộ các mẫu trong training set. Huấn luyện nhằm giúp hệ thống đạt được độ sai khác thấp hơn so với lúc ban đầu.
SL thường có hiệu năng cao hơn các phương pháp khác nhưng quá trình huấn luyện tốn kém hơn nhiều do phải gán nhãn cho từng mẫu.
Học không giám sát (Unsupervised learning, UL)
Khác với SL, mục tiêu của UL là học ra những hàm mô tả những cấu trúc ẩn trong dữ liệu. UL nhằm giải quyết những bài toán mà lượng dữ liệu có nhãn là rất ít hoặc không có, hoặc do những đặc trưng của bài toán mà dữ liệu có gán nhãn là không cần thiết.
Ví dụ chúng ta có một lượng lớn khách hàng với những sở thích khác nhau và muốn có một nhân viên hỗ trợ khách hàng cho mỗi nhóm sở thích. Ở đây chúng ta không cần quan tâm sở thích cụ thể của một người là gì mà chỉ muốn những khách hàng có cùng sở thích thì sẽ được hỗ trợ bởi cùng một nhân viên. Chúng ta sử dụng thuật toán phân cụm (clustering), ví dụ như k-means, để nhóm những khách hàng có cùng sở thích lại với nhau dựa theo một độ đo (measure) về sự giống/khác nhau về sở thích giữa 2 người.
Semi-supervised learning (học bán giám sát) là một phương pháp kết hợp giữa UL và SL để giải quyết những bài toán có ít dữ liệu có gán nhãn.
Học tăng cường (Reinforcement learning, RL)
Khác với 2 phương pháp trên, RL không học từ những tập dữ liệu có sẵn mà nó liên quan tới việc điều khiển một/nhiều tác tử (agent) đưa ra những hành động (actions) trong một môi trường (environment) một cách hợp lí để cực đại hóa giá trị phần thưởng tích lũy (cummulative reward).
Ví dụ chúng ta có một robot (agent) với khả năng quan sát hạn hẹp, ở trong một môi trường với nhiều chướng cạm bẫy và phần thưởng. Mục tiêu của robot là tìm ra cách hoạt động thu được nhiều phần thưởng nhất và tránh được các cạm bẫy. Để đạt được điều đó, robot phải trải qua quá trình dò tìm, khảo sát môi trường xung quanh và dần xây dựng nên một mô hình về môi trường đó. Quá trình học này khác với SL, UL vì dữ liệu về môi trường là không sẵn có mà phải được khám phá dần dần qua nhiều lần thử nghiệm.
SL và UL là hai phương pháp phổ biến nhất trong ML nhưng RL cũng là một phương pháp cực kì triển vọng và đang phát triển mạnh mẽ trong thời gian gần đây khi nó được kết hợp với SL và UL.
Deep learning
Deep learning ban đầu là một tên gọi khác (nghe cho oách) của mạng nơ-ron nhân tạo, Artificial Neural Networks (ANN, NN) nhưng hiện nay nghiên cứu về Deep learning thực sự đã vượt xa hơn ANN đơn thuần rất nhiều nên sẽ là thiếu sót nếu nói Deep learning chỉ là ANN. Trong thời gian khoảng 10 năm trở lại đây, DL đã tạo nên một cơn sốt chưa từng có trong khoa học máy tính khi nó lần lượt đánh bại hầu hết các thuật toán khác trong hàng loạt các bài toán của ML. Một số nhà khoa học còn kì vọng đây là thuật toán tổng quát đầu tiên có thể giải quyết nhiều bài toán khác nhau.
Mặc dù một số báo lá cải khoa học thường cố gắng làm cho mọi người nghĩ rằng DL là một thứ mới xuất hiện trong khoảng chục năm trở lại đây, lịch sử của DL bắt đầu từ khoảng 50, 60 năm trước (trích Juergen Schmidhuber: Deep Learning RNNaissance). ANN là một trong những nỗ lực mô phỏng não bộ và quá trình tư duy của não bộ. ANN tương tự như mạng nơ-ron thực gồm những nơ-ron bao gồm phần thân và những kết nối (synapses) tới các nơ-ron khác. Tuy nhiên, mỗi nơ-ron trong mạng nơ-ron nhân tạo đơn giản hơn nơ-ron thực rất rất rất nhiều và đương nhiên là cũng có năng lực xử lí kém hơn rất nhiều lần. Những ANN lớn nhất hiện nay cũng có số nơ-ron nhỏ hơn số nơ-ron trung bình trong não rất nhiều lần. Một ANN cỡ lớn có thể có vài chục ngàn nơ-ron trong khi số nơ-ron trong não ước tính là khoảng trên 100 tỉ và số lượng kết nối trung bình của một nơ-ron thực là khoảng vài chục ngàn.
Việc đơn giản hóa quá mức như vậy (over simplication) nhằm giúp việc huấn luyện mạng có thể chấp nhận được trong thực tiễn. Để huấn luyện một mạng nơ-ron, trung bình cần tới vài giờ, vài ngày hoặc vài tuần trên những máy tính cực mạnh (những GPU hiện đại với năng lực tính toán khoảng 5-10 ngàn tỉ phép tính dấu phẩy động mỗi giây (5,000-10,000 gflops) và những hệ thống lớn cần hàng chục thậm chí hàng trăm GPU như vậy). Và mặc dù đã được giản lược như vậy, ANN vẫn phức tạp hơn phần lớn các thuật toán khác trong ML và có hiệu năng vượt trội. Độ phức tạp quá lớn của ANN cũng làm những nhà khoa học đau đầu khi chưa thể hiểu rõ và lí giải được tại sao ANN lại hiệu quả như vậy (xem thêm: The unreasonable effectiveness of RNN).
ANN hiện nay đang được nghiên cứu mạnh mẽ tại nhiều nơi trên thế giới và được ứng dụng trong nhiều ngành khoa học khác nhau, không chỉ riêng khoa học máy tính. Nhiều nhà khoa học tin rằng đây là mô hình toán học đầu tiên cho phép giải quyết nhiều loại bài toán khác nhau chỉ bằng một thuật toán duy nhất (universal learning algorithm). Mặc dù ý kiến này còn đang được tranh luận và nó có vẻ đi ngược lại “No Free Lunch Theorem” cho rằng không có một thuật toán nào có thể đạt được kết quả tốt trên mọi loại bài toán, nhưng nó cho thấy kì vọng lớn lao vào tiềm năng của ANN.
Trong khóa học này chúng ta sẽ cùng tìm hiểu về ANN từ những mô hình sơ khai nhất của những năm 1950 tới những mô hình hiện đại nhất của 2015, 2016. Và hi vọng là trong quá trình đó, chúng ta sẽ dần hiểu được bản chất của ANN để có thể ứng dụng và phát triển nó. Chúng ta sẽ xây dựng những ứng dụng rất thú vị của ANN trong CV, NLP như nhận dạng chữ viết tay, xây dựng mô hình ngôn ngữ (language model), viết văn và soạn nhạc bằng ANN, …
Một số demo thú vị của những mô hình mà chúng ta sẽ xây dựng trong khóa học này như sau:
Sinh chữ viết tay với LSTM
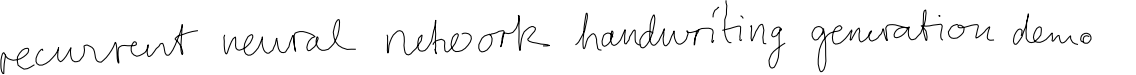
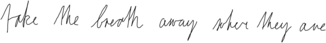
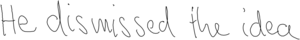
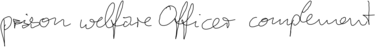
Demo bởi Alex Graves, học trò của Juergen Schmidhuber. Các bạn có thể đoán được đâu là chữ do người viết đâu là do ANN sinh ra không?
Nhận dạng chữ viết với Convolutional Neural Networks (CNN)
Video Demo bởi Yann Lecun, người phát minh ra CNN.
Vẽ tranh với ANN


Những bức tranh này đã được rao bán trên ebay. Bài báo gốc: A Neural Algorithm of Artistic Style, Leon A. Gatys, Alexander S. Ecker, Matthias Bethge.
Soạn nhạc với LSTM
Tài liệu tham khảo
Khóa học này sử dụng tài liệu từ các khóa học sau:
- Deep learning, Nando de Freitas, Oxford University, 2015
- Introduction to Machine learning, Andrew Ng, Stanford University, 2015
- Learning from data, Yaser Abu Mostafa, Caltech, 2012
- Deep learning summer school 2015, University of Montreal, 2015
- Neural networks, Geoffrey Hinton, University of Torronto, 2012
Và các tài liệu:
- Deep learning, Ian Goodfellow, Yoshua Bengio, and Aaron Courville
- Pattern recognition and Machine learning, Christopher Bishop
- Machine learning: a probabilistic perspective, Kevin Murphy
- Learning from data, Yaser Abu Mostafa
Cùng các bài giảng, nói chuyện khác của Geoffrey Hinton, Yoshua Bengio, Yann Lecun, Juergen Schmidhuber, Andrew Ng, Alex Graves, …
Với mỗi trích dẫn, hình ảnh hoặc video, … sẽ có dẫn nguồn cụ thể.